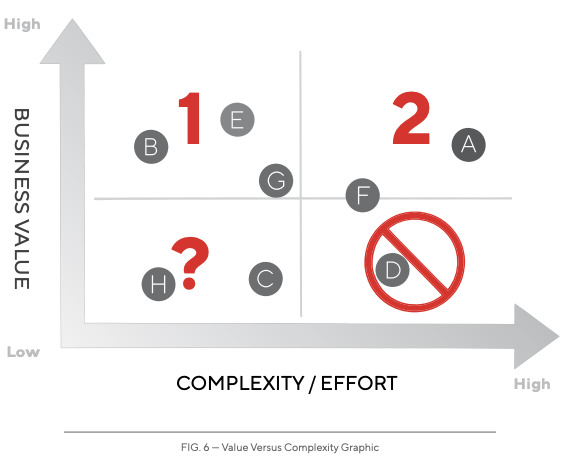
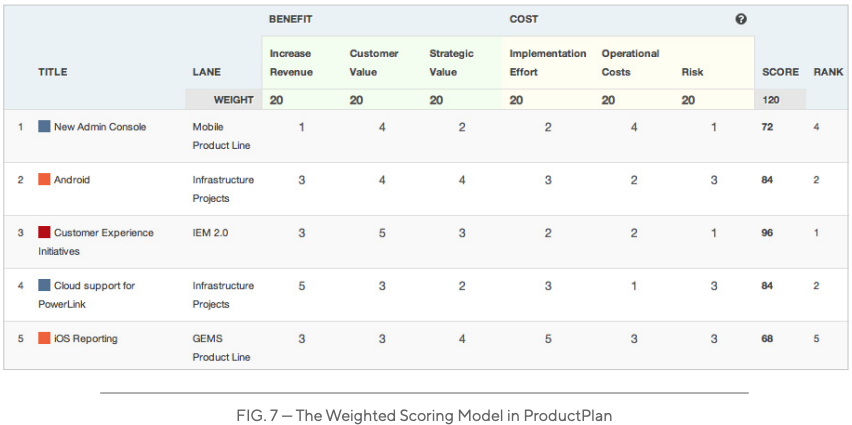
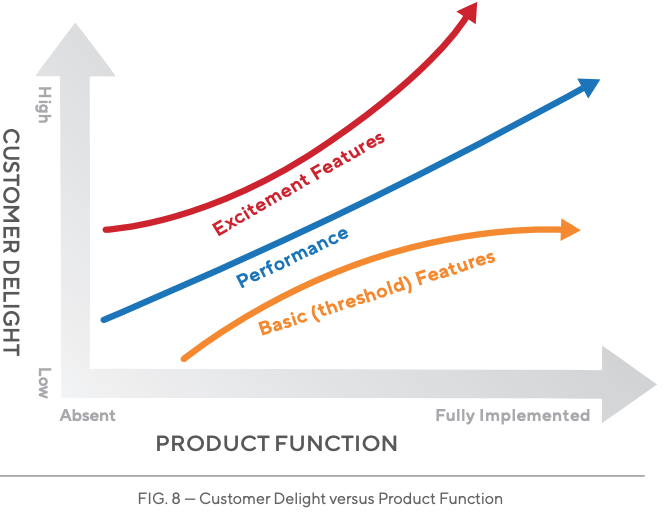
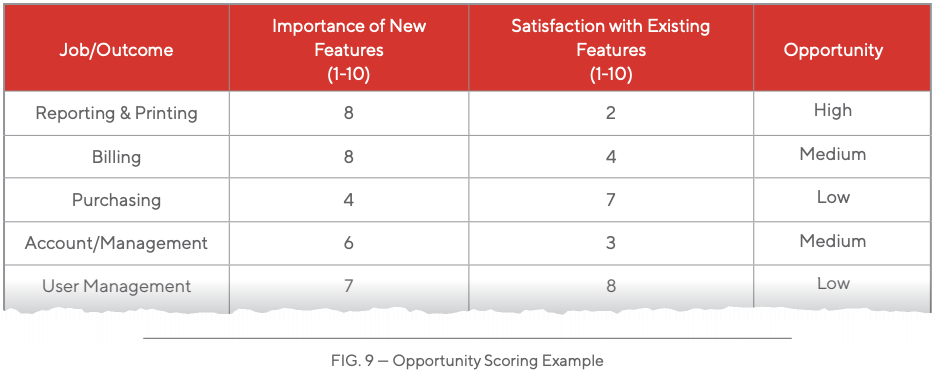
The way marketing works is evolving. Brands need to adapt to stay ahead. Social Media Marketing is here to stay
Social media is one of the most powerful ways to reach and engage with customers. Universally used by consumers and brands – social media is one of
the most effective channels to connect with your audience.
Influencer marketing continues to grow at double-digit rates because it’s effective.
People are tired of being interrupted by ads and trust recommendations from those they follow – expect to see more brands partner with influencers to promote their products
It costs four to ten times more to acquire a customer than to retain one. To keep your customers around, use social media to support, communicate and engage. A good social media presence will translate into a better relationship with your brand.
Social media marketing has matured over the 10 years to become an integral part of the marketing mix for large and small businesses. It can have a significant and on your bottom line and can be a powerful marketing tool.
Whether you are trying to reach a local audience or launching a brand nationwide, social media marketing should be considered as part of your marketing strategy.
The Four C’s of Social Media Marketing
Communities
The most important element of a social media marketing campaign is people: real people, not Facebook pages, or LinkedIn profiles.
Unlike other marketing channels; eg banner ads or email, social media marketing needs to be social.
Building your target community database is similar to building an email list with one important exception: your intent is to facilitate conversation that builds interaction – not broadcasting a single message to a list.
Conversations
Reciprocity is the currency of social networking. To realise ROI in social media marketing, you have to believe in social karma.
Conversations are happening all over social media. Millions of these conversations are about products and services.
Asa brand owner do not be afraid to talk, share, educate and ask questions. Look at social media as a way to humanise your brand. If consumers like see and like you, they will like your company.
Be authentic, social and friendly. People engage with 11.4 pieces of content before making a purchase. Give your audience value they can’t get anywhere else. Give them the incentive they need to click and buy!
Channels
Each social channel comes with a unique social etiquette and language for enabling social conversations.
LinkedIn and Twitter
A lengthy and informative blog post might work for LinkedIn, but that blog wont work on Twitter. You need to create a cut-down or visual representation of the same content.
Facebook
The Facebook audience responds best to visually engaging posts that are entertaining, informative, inspirational or rewarding. The best content types to use are photos, videos, quizzes, competitions.
Instagram
Use Instagram to inspire and engage your potential customers. You must commit to sharing a frequent stream of high quality, inspiring and engaging photos and
videos.
Campaigns
An advertising campaign is designed, measured and optimised across target audience segments, message variations and advertising channels. In the same way your social media campaign needs to be designed, measured and optimised across target communities, various topics of conversation, and social media channels.
The first step to creating a social media marketing strategy is to establish
your objectives and goals. Without goals, you have no way to measure your social media return on investment (ROI).
Knowing who your audience is and what they want to see on social is key to
creating content that they will engage with. This knowledge is also critical for planning how to develop your social media audience into customers for your business.
Creating audience personas – eg simplified categories of buyers of your product.
Each persona will have different demographics, buying motivations, common
buying objections, and emotional needs.